
寻找AI普惠时代的方舟:“水灵灵”的CPU驱动AI推理驶向深海
在很长一段时间里,围绕GPU的抢购、囤货此起彼伏,人们对其每款新品都翘首以待,而CPU似乎已被遗忘在角落。

不过,根据科技发展史中屡试不爽的定律,“一家独大”的局面很难持久,对GPU强势地位的挑战如期而至,算力“去魅化”也拉开序幕。
第一波的领头羊是算力设备供应商,很多服务器厂商强调以“系统创新”提升集群效率,并得到存储、网络等领域厂商的呼应。它们想借助算力、存力、运力的协同效应,大幅降低对单一供应商的过度依赖。
第二波的推动者是云计算服务商和大模型厂商,通过类似多米诺骨牌式的连环降价,让AI算力和算法不再拒人千里,大模型应用的门槛显著降低。这在一定程度上打破了人工智能的神秘感,落入凡尘的AI更具亲和力。
事实上,上述变化折射出的是更宏大的主题——AI普惠时代已经来临,AI算力与通用算力之间的鸿沟会被逐渐填平,AI推理对算力的需求将超越AI训练。此时,真正的主角可以“水灵灵”地登场,几经波折的CPU有望上演“王者归来”的大戏。
这既是对CPU价值的重新评估,也是加速AI普惠进程的必由之路。尤值一提的是,作为应用普惠的开路先锋,AI推理已成为大模型落地的核心动力,这艘巨轮正带领千行百业驶向数字化转型的汪洋大海,而CPU恰是“底舱”中不可或缺的关键角色。
在充满不确定性因素的“深海”中,AI推理不得不面对风暴的冲击与暗礁的突袭,CPU能否发挥“压舱石”的重要作用?
打造AI推理新“硬核”:CPU的价值归位与崭新挑战
从众多AI巨头近期发布的最新一期财报来看,AI推理收入在其业务中的占比明显提升,且未来增速被普遍看好,AI推理对算力的总需求超越AI训练并不遥远。
这是AI加快渗透进程的信号,也为CPU施展身手提供了巨大舞台。由于AI推理并不推崇“大力出奇迹”,更强调持续运算与低延迟,兼具高性能、低能耗、高性价比等多重优势的CPU备受青睐。即使在GPU声势最鼎盛的时期,CPU在AI推理领域的价值也得到广泛认可。
当然,CPU的价值归位并非一帆风顺,其必须应对AI推理进化过程中衍生出的诸多挑战。一方面,AI推理的场景纷繁复杂,经常在不同的软硬件平台及云网边端间反复切换,对CPU在各类设备上的通用性与综合指标表现要求颇高;另一方面,大模型的演进使AI推理任务涉及大量复杂运算和尖端场景,需要频繁访问模型参数和中间数据,对CPU的性能、缓存、IO带宽带来严峻考验。

迈向AI推理新境界:CPU“三级驱动”实现全面跃迁
显而易见,单纯依靠性价比打天下的阶段一去不返,CPU要在AI推理大行其道的新时代谋求更多发展空间,必须完成核心能力的全面跃迁。
参考火箭系统在航空航天领域的演进轨迹,也许可以为CPU的进阶之路提供借鉴。为了使航天器达到第一宇宙速度,顺利进入运行轨道,三级火箭应运而生——通过每一级火箭系统接力燃烧,航天器的飞行速度不断加快,最终达成预期目标。
当下,AI推理的航船正从风平浪静的浅水区驶向“风浪越大鱼越大”的深水区,CPU作为算力底座的核心角色,只有实现类似火箭“三级动力”的蜕变升级,才能真正为各个行业的数智化转型保驾护航。
在大模型应用迈向纵深的背景下,更高的CPU频率是AI推理适应复合型工作负载需求的“一级动力”。借助AI推理实现业务创新是行业客户使用大模型的主要目标,这意味着CPU可能同时处理来自成千上万个源的数据推理请求,必然要求其在各种工作负载运行中提供更高的核心频率,最好能支持更多的核心数同时达到最高频率。

在打造“一级动力”的赛道上,第四代AMD EPYC显然处于领跑阵营。针对客户需求的痛点,第四代AMD EPYC采用最新的ZEN 4技术架构,时钟速率提高14%,每时钟周期执行指令数增加15%~24%——更高的核心频率促进CPU整体性能大幅改善,显著增强AI推理应对纷繁工作负载的能力。
当信息化、数字化与智能化需求叠加在一起,更快速高效的数据传输能力是CPU驱动AI推理的“二级动力”。很多行业客户为了赶上AI浪潮的节拍,要先弥补在信息化建设和数字化转型阶段的不足,重构以新一代CPU为核心的算力底座即是其必修课。在AI推理中,CPU担纲重任,其会与存储、网络以及其他硬件设备频繁交换数据,对I/O水平要求更高,且应具备出色的内存传输速度和指令集优化能力。
值得关注的是,第四代AMD EPYC拥有更强大的内存与I/O,引入DDR5内存并支持多达12个通道,其中Genoa家族所有型号均完整支持4800MT内存,Genoa插槽能够提供460.8 GB/s的理论峰值内存带宽,双路理论支持内存带宽最大可达920Gbps;同时,为应对AI推理中矩阵和向量计算的挑战,其具备灵活高效的AVX-512扩展指令集,支持BF16数据类型以提高吞吐量,双周期、256位流水线设计有助于提高AI推理的运行效率。
面对高性能计算、科学计算等缓存敏感型场景的挑战,更大的三级缓存是CPU助力AI推理攻坚克难的“三级动力”。在复杂场景的AI推理中,CPU的缓存能力往往成为“最短的木板”,制约相关任务的执行效率和完成效果。颇具开创性的三级缓存是破解难题的有效方式,能帮助行业客户扫除应用落地的障碍。
作为CPU核心技术创新的引领者,AMD不断打破三级缓存的天花板,在超越自我的同时达成客户预期。AMD第四代处理器“Genoa”系列除显著提升L2容量至每核心1MB外,保持每8个核心共享32M三级缓存;同时,Genoa-X提供每8个核心共享96M三级缓存,为AI推理业务实现“缓存自由”创造了必要条件。

CPU助推AI算力与通用算力汇流入海
站在更长远的视角,伴随人工智能通用化进程不断加快,传统通用算力与AI算力之间的融合正在成为新的潮流,而处在交汇点上的CPU无疑将扮演举足轻重的角色。
目前,基于以CPU为核心的通用服务器进行大模型推理,不再是什么新鲜事。越来越多的行业用户摒弃了“烧钱”模式,更多依托高性能CPU构建新型算力底座,合理平衡CPU与GPU的配置关系,真正享受到AI时代的普惠红利。
令人欣喜的是,CPU自身也没有停止进化的脚步。作为拥有高性能GPU、CPU及各种平台解决方案的行业领头羊,AMD始终走在CPU技术创新的前列,其第四代处理器包括Genoa、Genoa-X、Bergamo、Siena等系列,不仅在前面提到的各项核心指标上屡创佳绩,而且为云原生、边缘计算等细分领域提供量身定制的解决方案,打造出AI时代CPU的新标杆。
在数智新世界的入海口,AI算力通用化的灯塔已经点亮。这里不再是独角戏的舞台,CPU与GPU以及FPGA、TPU、ASIC等伙伴们将携手起舞,下一段航程更加精彩纷呈。
内容转载自:IT创事记


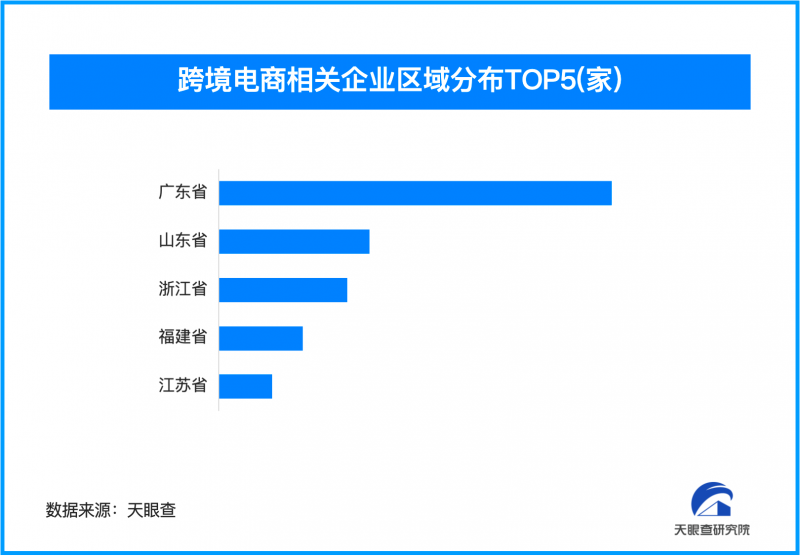

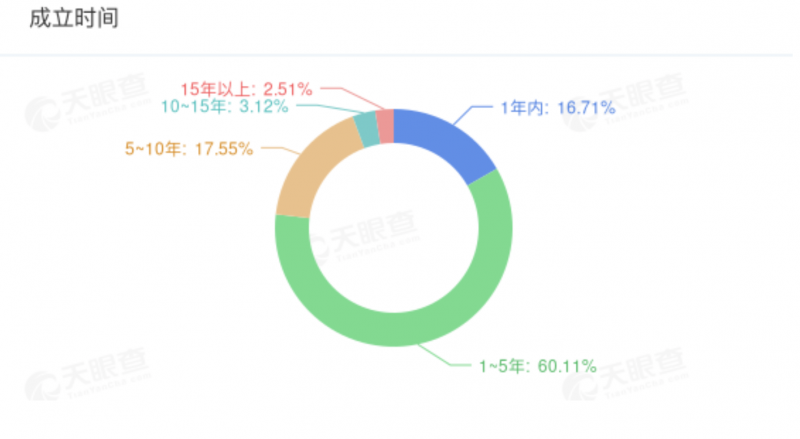
-
1
![]() 为真正驾驶者而来 阿斯顿·马丁全新Vantage震撼上市
为真正驾驶者而来 阿斯顿·马丁全新Vantage震撼上市
2024-04-22
-
2
![]() 全媒社携手澳大利亚城市明星网红,打造最新合作计划
全媒社携手澳大利亚城市明星网红,打造最新合作计划
2024-04-15
-
3
![]() 【承势聚力接“贵”客】抢抓机遇 加快建设贵州大数据电子信息产业集聚区
【承势聚力接“贵”客】抢抓机遇 加快建设贵州大数据电子信息产业集聚区
2024-04-15
-
4
![]() 2024年全景相机排名
2024年全景相机排名
2024-03-29
-
5
![]() 2024年中国运动相机实力排名
2024年中国运动相机实力排名
2024-03-27
-
6
![]() 以后买旗舰除了第三代骁龙8手机,还可以少花钱买新生代8s
以后买旗舰除了第三代骁龙8手机,还可以少花钱买新生代8s
2024-03-20





